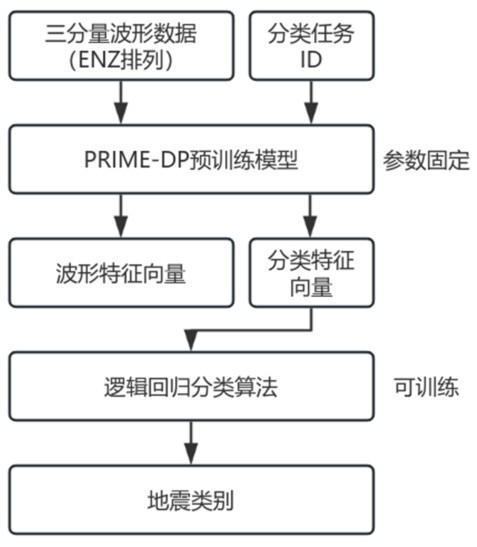
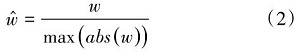训练过程中为方便对比,所有模型均统一为1e-3学习率固定不变。实验和评估过程中我们使用测试集来进行,统计的参数为查全率(Recall, R)、查准率(Precsion,P)、F1分数(F1-Score)和混淆矩阵。在此我们定义被正确分类的样本数量为真阳性样本(True Positive samples,TP),非本类样本而被检测为本类的数量为假阳性样本(False Positive samples,FP),是本类样本而没有被正确分类的为假阴性样本(False Negative samples, FN)。此时P、R、F1计算方式为公式3:
混淆矩阵为不同样本被分类为不同类别的数量和频率。
在分类过程中如果一个事件被多个台站接收到,那么我们在计算的过程分别对每个台站进行分类,最后保留数量最多的类别作为本个地震的类别。按这种方案进行统计结果如表1所示。
统计的混淆矩阵如图4所示:
表1 不同类别的事件的精度统计Table 1 Classification accuracy of different types of event
图4 分类结果混淆矩阵Fig.4 Confusion matrix of classification results
可以看到,在分类过程中总的精度为94.3%,如表所示,在分类的过程中对于塌陷和爆破的分类精度较低,二者深度较浅,具有一定的相似性。而对于微地震事件的分类精度达到了98.3%,这是因为微地震事件特征较为明显,其持续时间较短, S波不发育。我们将不同预测结果绘制成图5:
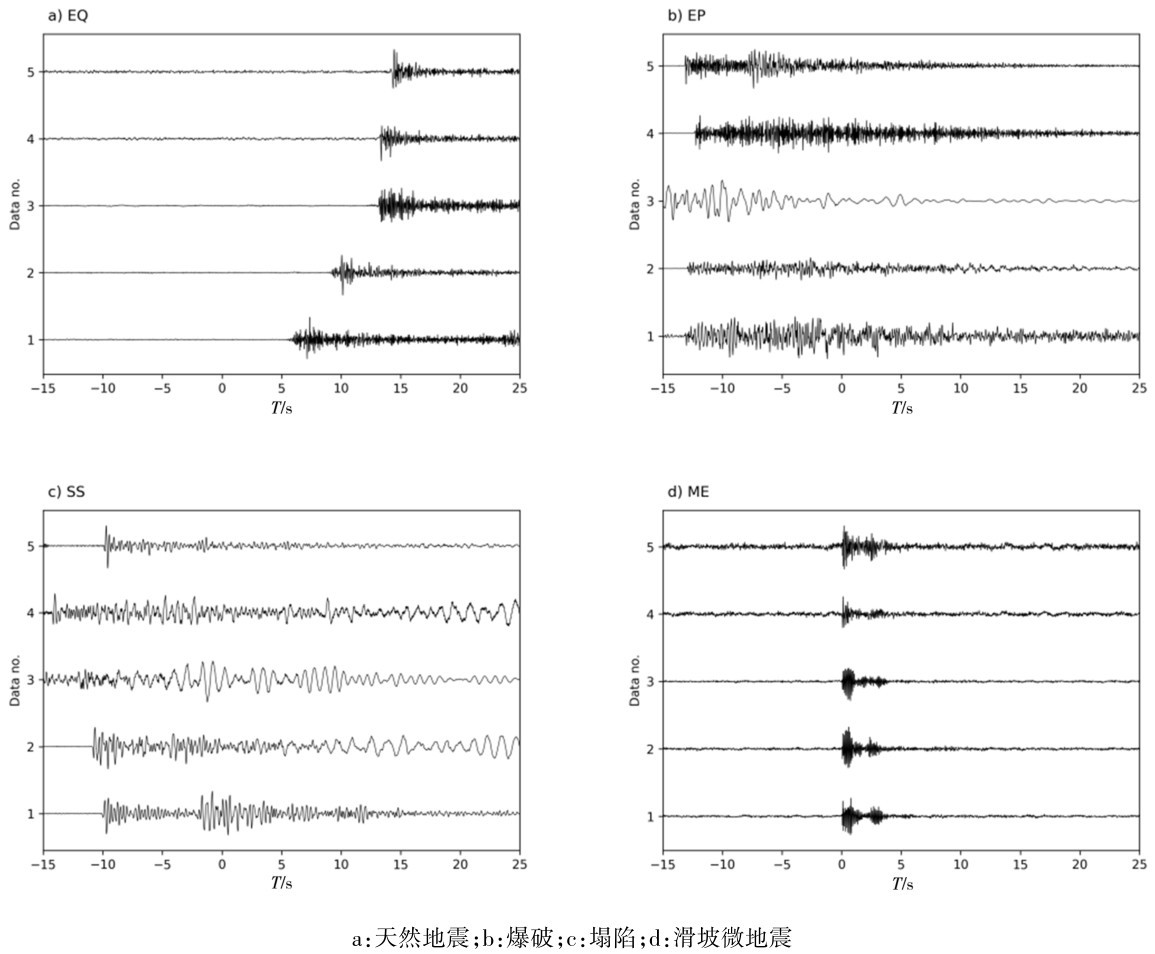
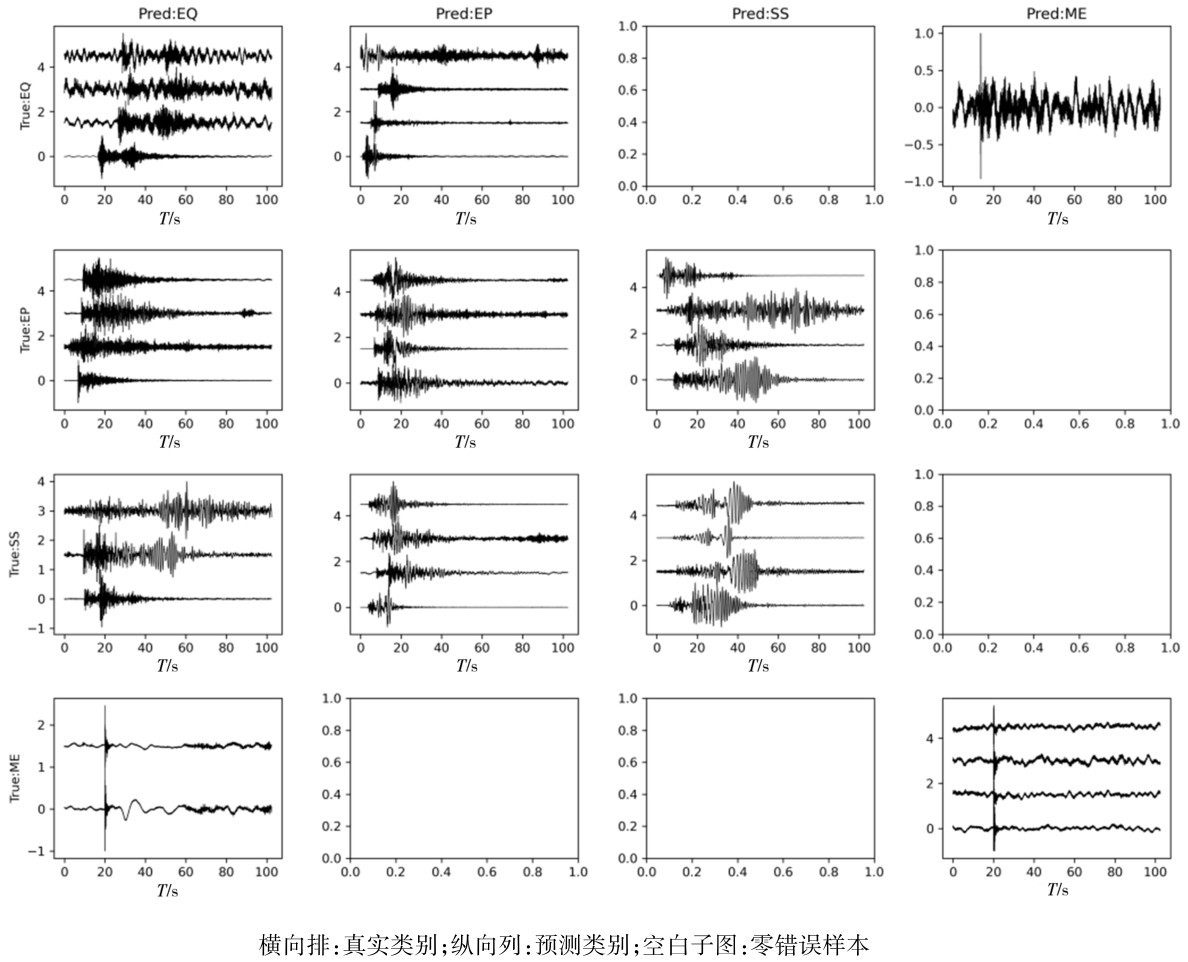
图5 基于垂直分量的不同波形预测结果图Fig.5 Prediction results of different waveforms based on vertical components
如图5所示,我们绘制了被误拾取的结果图,这是以单个波形为基础绘制的。可以看到天然地震被分类为滑坡微地震事件的波形信噪比较低,此时难以有效的进行区分,而被分为爆破事件的波形中P波振幅较大,S波振幅较小。而爆破和塌陷的波形则较为复杂,在被划分为塌陷的爆破事件中则具有较多的低频成分,这与塌陷的波形时接近的。在被分为天然地震事件的微地震事件中,可以看到明细的微地震事件,而在微地震事件之后有少量噪声,此部分噪声导致识别过程中被分类为天然地震事件。
为测试预训练模型的作用同时测试深度特征的可用性,我们使用黎炳君等(2021)的模型进行了分类测试,测试与我们当前的模型进行了两种迭代,第一种迭代了与我们模型相同的1000次,第二迭代至训练数据精度不再变化,学习率均固定1e-3。另外我们在特征基础上构建了两层多层感知器模型,每层特征数量为128,使用GELU为激活函数,学习率固定位1e-3。测试结果如表2所示:
表2 不同模型精度对比Table 2 Precision comparison of different models
可以看到黎炳君等人迭代1000次结果精度是偏低的,分类精度79.4%,特别是对于天然地震的分类精度较低,这代表了模型在捕捉天然地震波形特征的过程中出现了问题。而迭代至精度不在发生变化后精度有所变化,分类精度为75.7%,不同类别精度有升有降。这是因为训练数据较少,受到样本随机性影响,精度会有所变化。但是相比于PRIME-DP预训练模型,精度依然较低,这说明预训练过程可以保证模型学习到波形本身的特征。使用MLP分类器精度为93.5%,这与逻辑回归模型相近,说明分类特征完备不需要非线性特征来进行更复杂的分类。