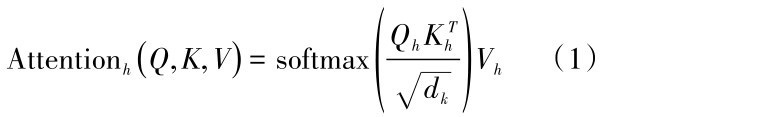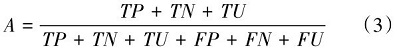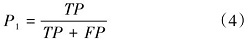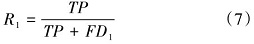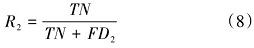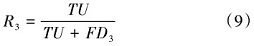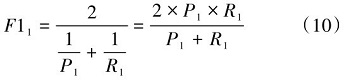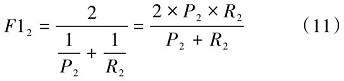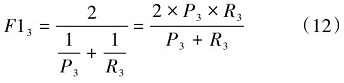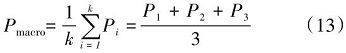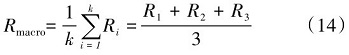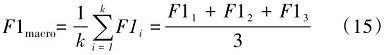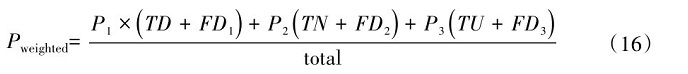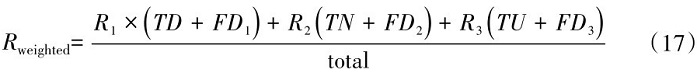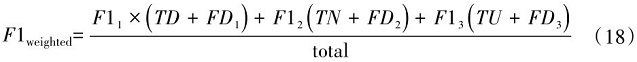3.2 多头自注意力机制
多头自注意力机制是指利用多个并行计算的注意力“头部”对输入的特征序列进行独立且互补的处理。具体来说,对于每一个单个的注意力头,都会独立地执行查询(Q, Query)、键(K, Key)和值(V,Value)向量的计算。完成所有单个头部的计算后,将各个头部输出的结果按照预设的方式(通常是拼接或级联)整合成一个单一的向量表示,这个综合后的向量能够融合不同注意力头捕捉到的不同类型的上下文信息,进一步丰富模型理解输入数据的能力。因此,可以说多头自注意力的核心是先通过多个并行的子空间注意力计算提取不同维度的语义关联,再将这些子空间的输出结果合并,形成最终的上下文感知表征[16]。
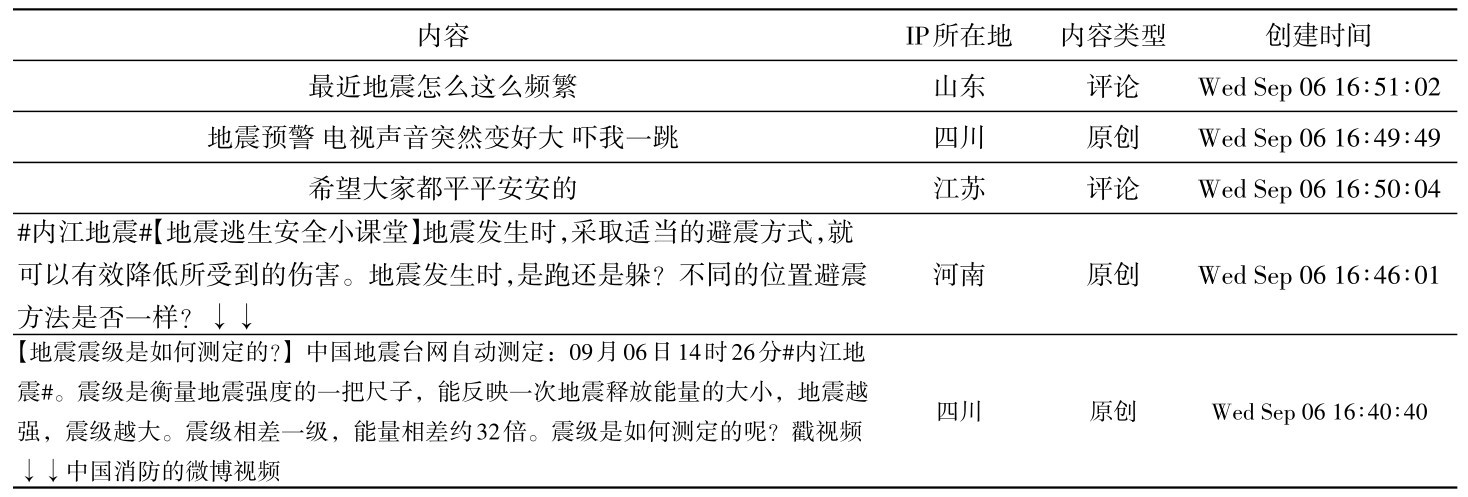
针对每一个单独的“头”来单独计算,并且使用softmax函数进行归一化处置,接着和对应的特征矩阵相乘,最后得到每个位置的加权值向量。单头注意力计算具体公式表示如下:
式(1)中, h表示头部编号, dk是键向量的维度(通常对角线上的分母开根号是为了稳定梯度和防止数值问题)。
多头并行计算及拼接具体公式为:
MultiHead (Q,K, V)=Concatenate( Attention1,(2) Attention2, ..., Attentionh)
3.3 CNN网络
卷积神经网络(Convolutional Neural Network, CNN)作为一种特殊的前向神经网络,近年来被学者广泛应用于自然语言处理领域,CNN的结构主要由输入层、卷积层与池化层、全连接层组成。如图1所示卷积层提取特征首先是以词向量矩阵形式表示文本,再通过不同大小的卷积核对矩阵进行扫描,在扫描过程中,卷积核所组成的滤波器的参数值固定不变,过滤后映射出新的特征图,该特征图上的所有元素都来自于参数一致的滤波器。
图1 CNN网络结构Fig.1 The framework of CNN
3.4 MHSAC-EPSA模型
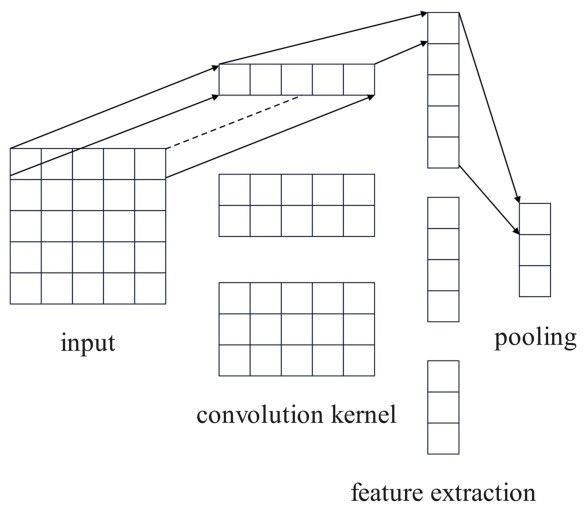
本文提出基于多头自注意力机制的CNN地震舆情分析模型(Multi Head Self Attention CNN-Earthquake Public Sentiment Analysis, MHSAC-EPSA),有效的将多头自注意力机制与CNN相结合。在对地震舆情数据进行处理时,将词向量作为输入,利用分层处理的方式将特征向量分割成多个并行的“注意力头”。其中,针对每个独立的“注意力头”执行更深层次的自注意力计算,从而达到对地震舆情数据中的每个词向量都进行差异化关注并及时分配不同权重的效果。最后再将每个“注意力头”的计算结果进行整合拼接,实现对长序列数据更高效、更细致全面的理解与挖掘,有效提升了地震舆情信息分析的精度与深度。模型框架如图2所示。
图2 本文构建模型框架Fig.2 The framework of proposed model
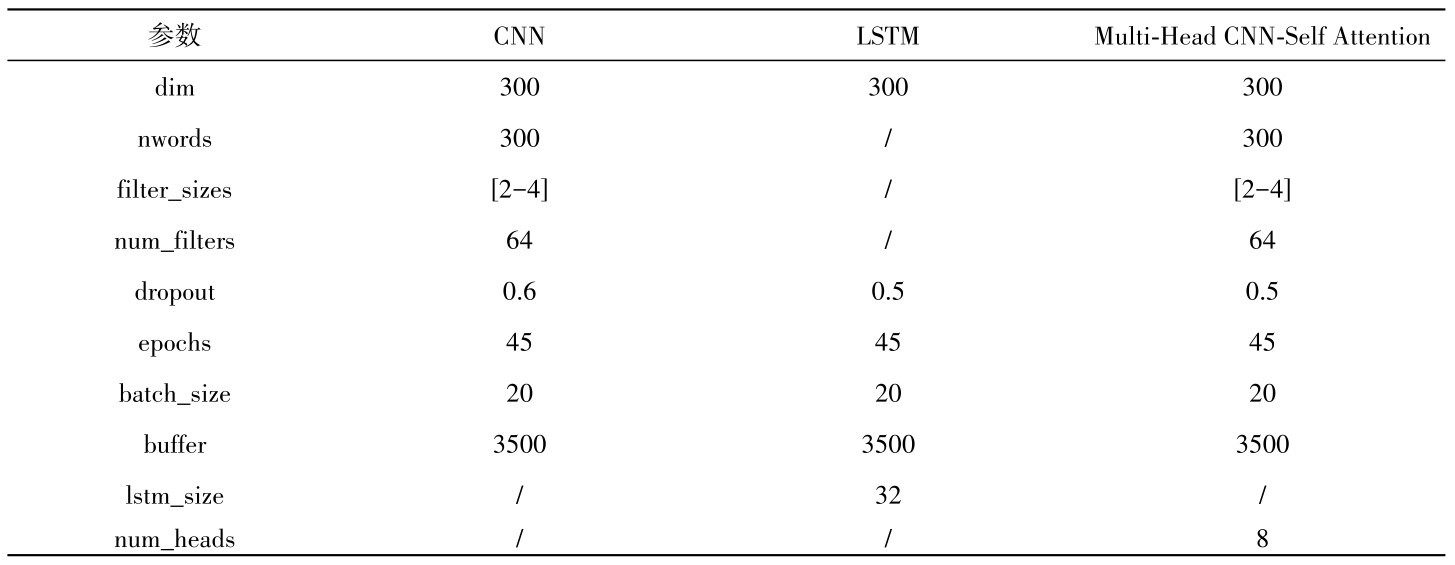
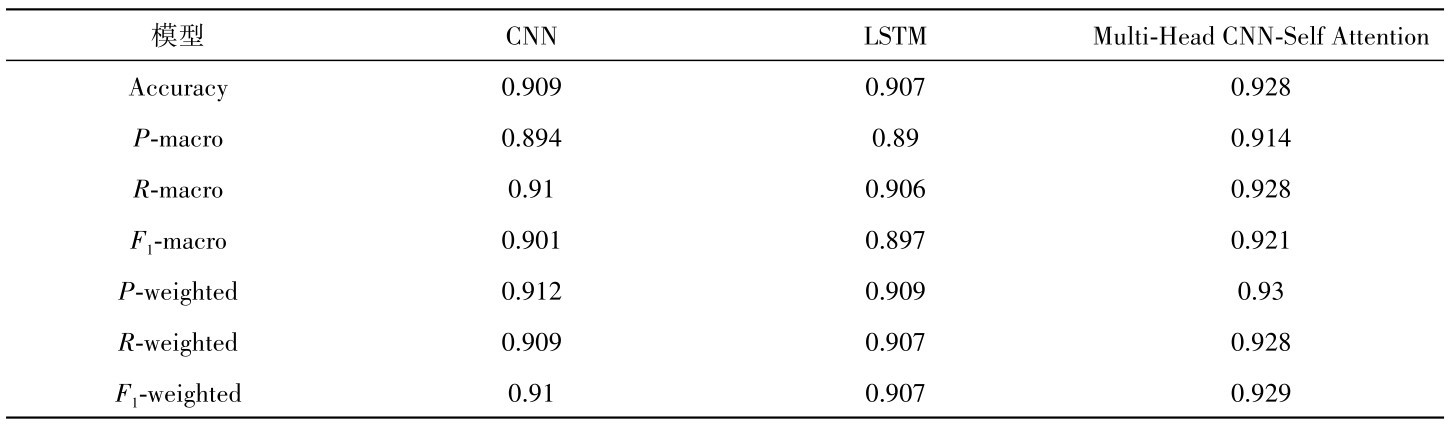
我们在输入层将文本数据转化为词向量矩阵,采用word2vec模型学习得到特征向量,输入到多头自注意力机制中,通过多头自注意力机制学习非连续词之间的语义相关特征,将上下文特征与词向量拼接得到句子的表示向量,输入到CNN卷积神经网络模型,使用卷积核对输入的特征矩阵进行卷积,得到全部特征向量。并且,利用超参数搜索选出最优模型参数,用以构建模型。模型实现震情文本分类的关键技术及算法描述如下:算法最优防御策略选取算法
输入 无标签文本T1,带标签文本T2
输出 文本分类标签
Begin
(1)word2vec模型对数据集训练,得到词向量词典W
(2)初始化Multi-head Self-Attention模型的参数
(3)for each sentence C∈T2
(4)从W中找出c中所有词语的词向量组成舆情文本矩阵C(S,L,U,1) =[ ],其中S指样本数量,L指每个样本的单词序列长度,U为词向量的维度,1为单通道。
(5)通过Multi-head Self-Attention对输入的嵌入矩阵C(S,L,U,1)进行拆分合并,并利用缩放点积以及softmax回归计算得到注意力权重矩阵O h ( B , H , Q() 其中B为样本的数量,H为序列的长度,Q为特征的维度,h为头部编号),并输出到下一层。
(6)通过CNN模型将矩阵O通过一系列的卷积操作和池化操作,提取出了文本数据的局部特征。每个卷积核可以看作是一个特征检测器,它会对多头注意力矩阵进行卷积操作,得到一个新的特征图P。
(7)P通过全连接层进行分类,得到文本矩阵c的类别标签。
end for
(8)使用RandomizedSearchCV进行超参数搜索,选出最佳模型参数进行训练和评估。
End