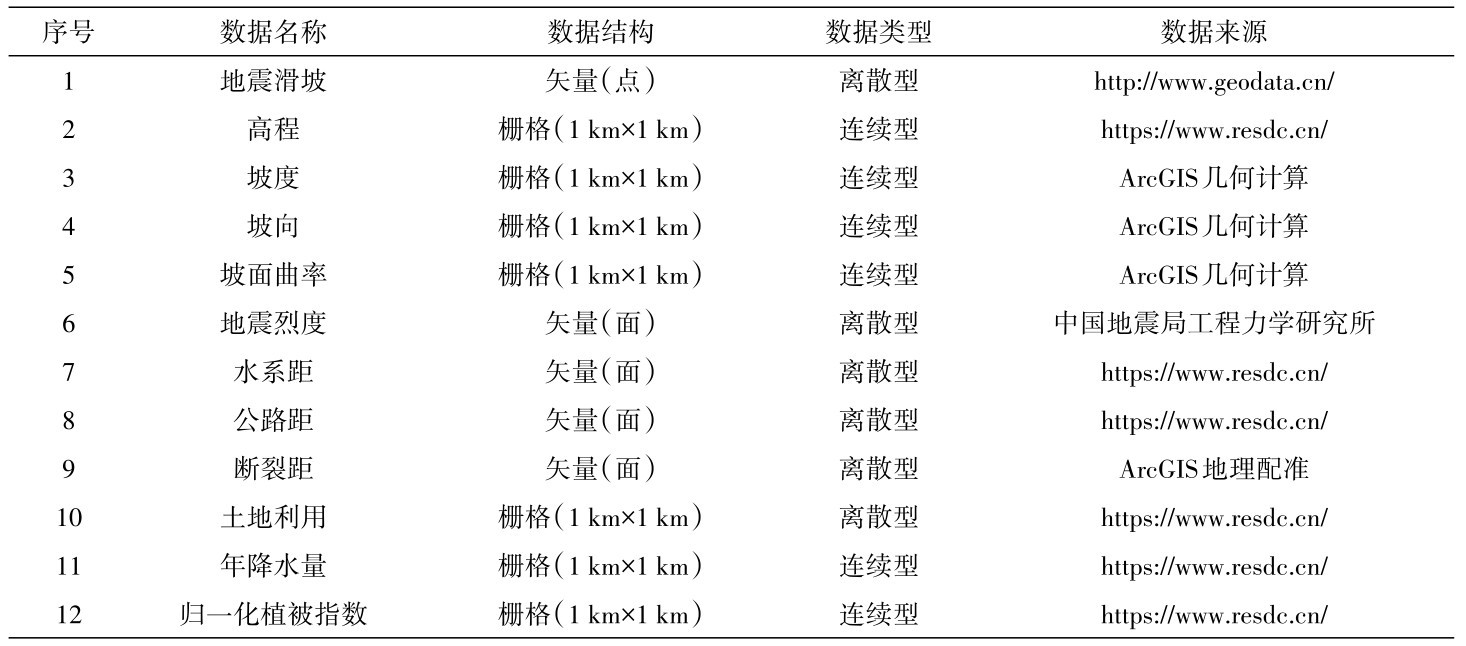
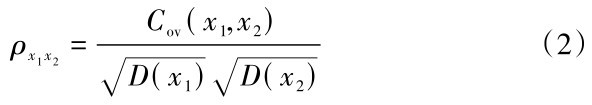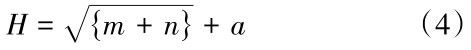4.1 人工神经网络结构确定
人工神经网络的首个模型及练算法被提出后,即被广泛地应用于模式识别与分类问题[36-37]。众多人工神经网络算法中以误差反传算法即BP(Back-Propagation)算法最为典型,本次研究即是采用误差反传算法进行数学建模。人工神经网络模型的建模流程可总结为如下五个步骤:确定网络结构、选择训练或学习算法、确定激活函数、调节权重及其它超参数、输出结果。
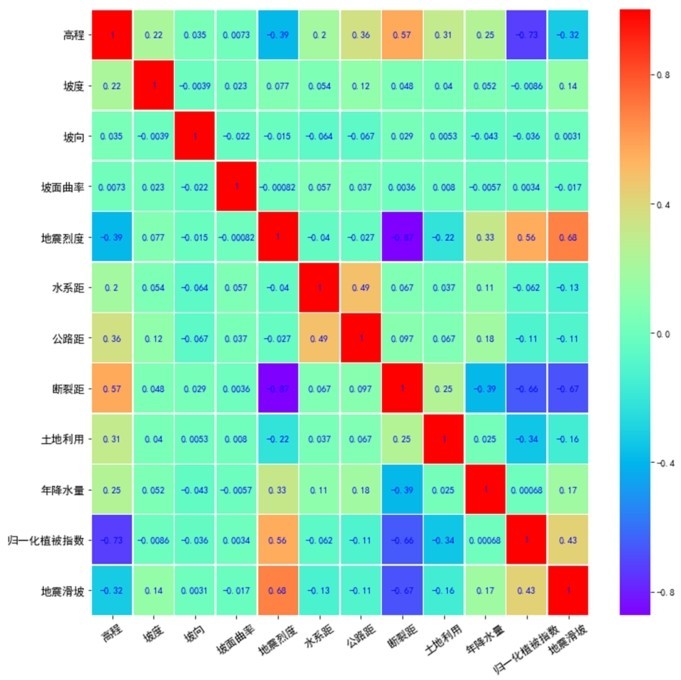
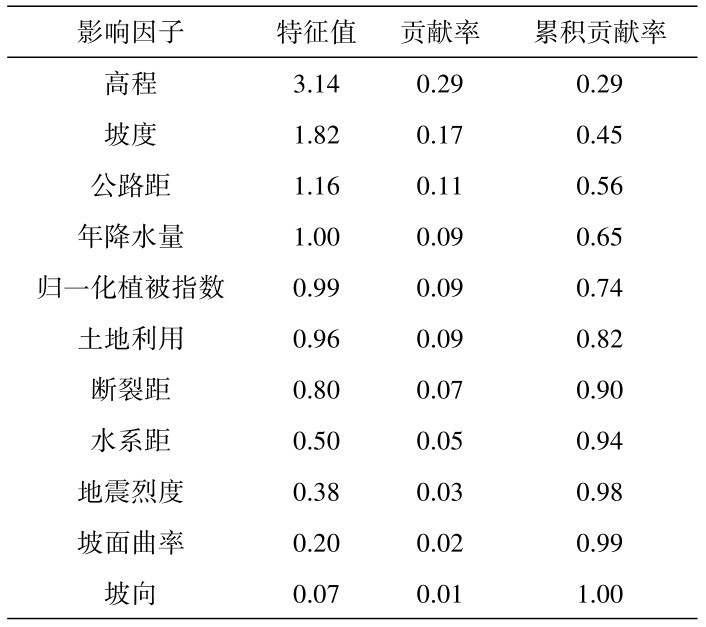
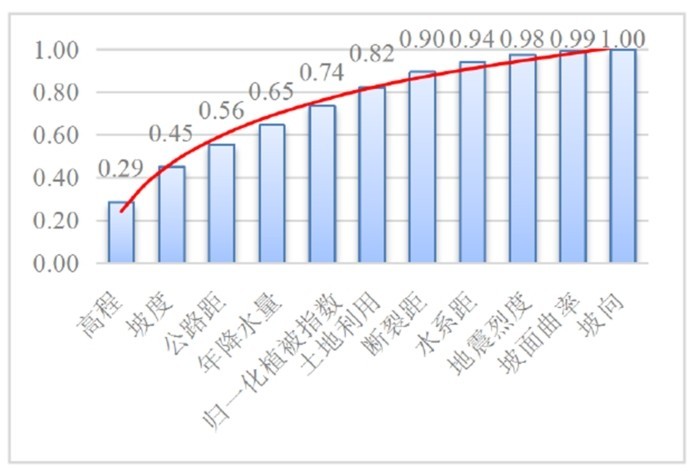
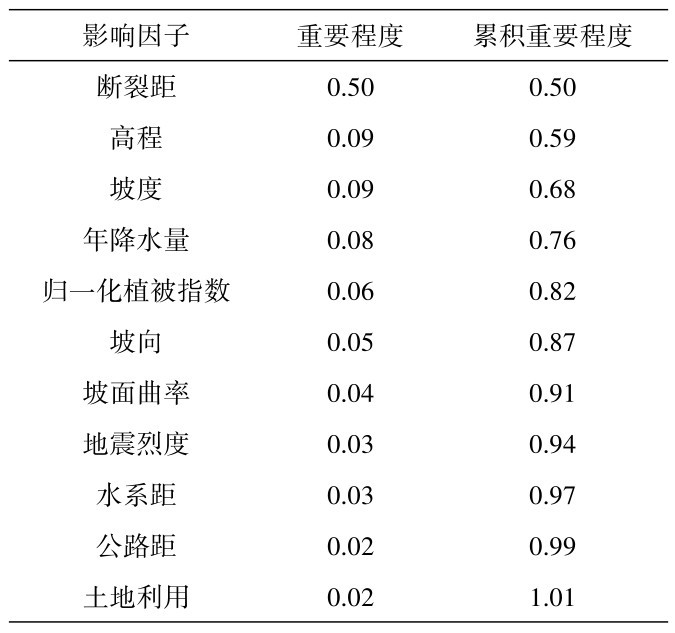
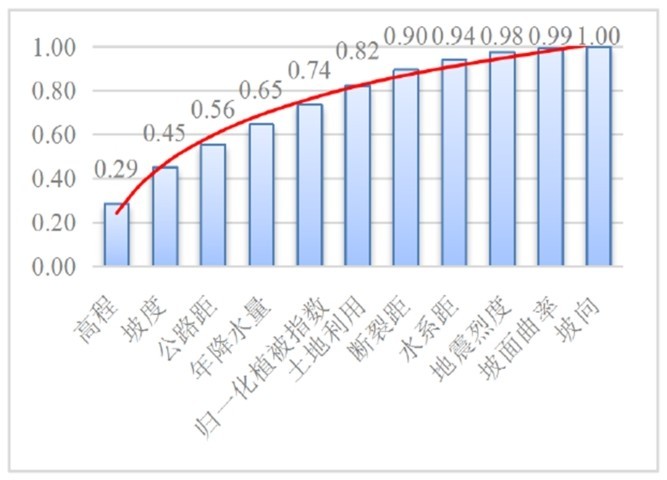
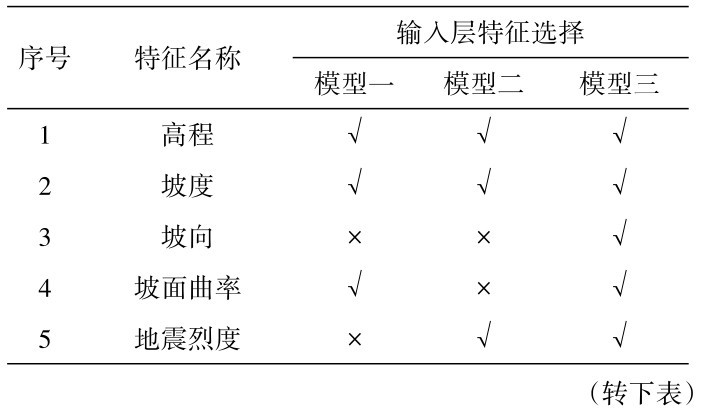
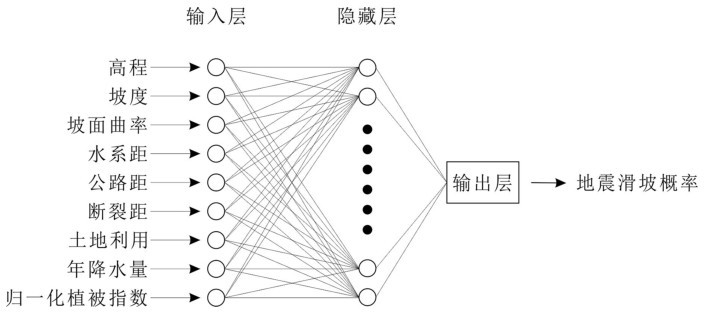
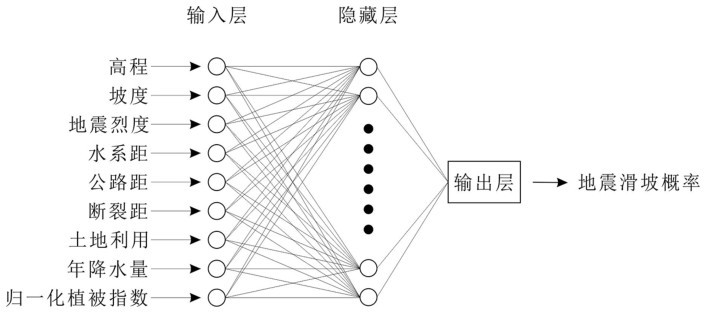
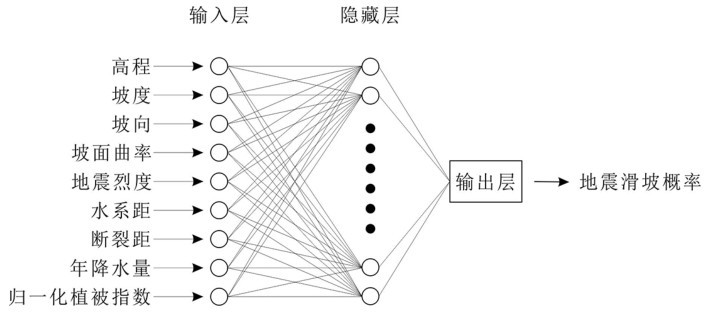
人工神经网络的整体结构可分为输入层、隐藏层和输出层三个部分。在使用人工神经网络进行数学建模之前,确定其基本结构是首先要解决的问题。根据上节对于特征的选择,基于相关性系数、主成分分析和Gini指数法确立三种模型输入层特征,并将上述三种模型定义为模型一、模型二和模型三。其中,输入层所选取的特征详见表4。
表4 人工神经网络输入层特征选择详表Table 4 Feature selection of input layer of artificial neural network
隐藏层方面,本次研究选取单隐藏层结构,因为在以前的研究中发现,当使用两个以上的隐藏层进行预测时,往往会导致对于预测结果的高估,并且,模型的训练时间也会大大增加[38]。隐藏层神经元的数量通常根据以下经验公式确定:
式(4)中:H为隐藏层神经元数量;m为输入层神经元数量;n为输出层神经元数量;a为1~10之间的调节常数。本文将隐藏层神经元个数定为6个。
在输出层的选择方面,选用双输出模式,通过正负样本的训练,最终直接输出相关概率值并将其作为衡量某点发生滑坡与否的标准。
综上所述,本次研究选用的三种人工神经网络模型结构如图6~8所示。
图6 模型一人工神经网络结构示意图Fig.6 Artificial neural network structure of Model 1
图7 模型二人工神经网络结构示意图Fig.7 Artificial neural network structure of Model 2
图8 模型三人工神经网络结构示意图Fig.8 Artificial neural network structure of Model 3
确定了本次研究的三种网络结构后,即可运用神经网络进行分类任务,其总体可概括为两个阶段:训练阶段和分类阶段。
分类阶段所进行的则是将训练好的神经网络模型通过前馈传播的方式对整个数据集进行分类,最终形成相应的预测结果。
4.2 模型训练
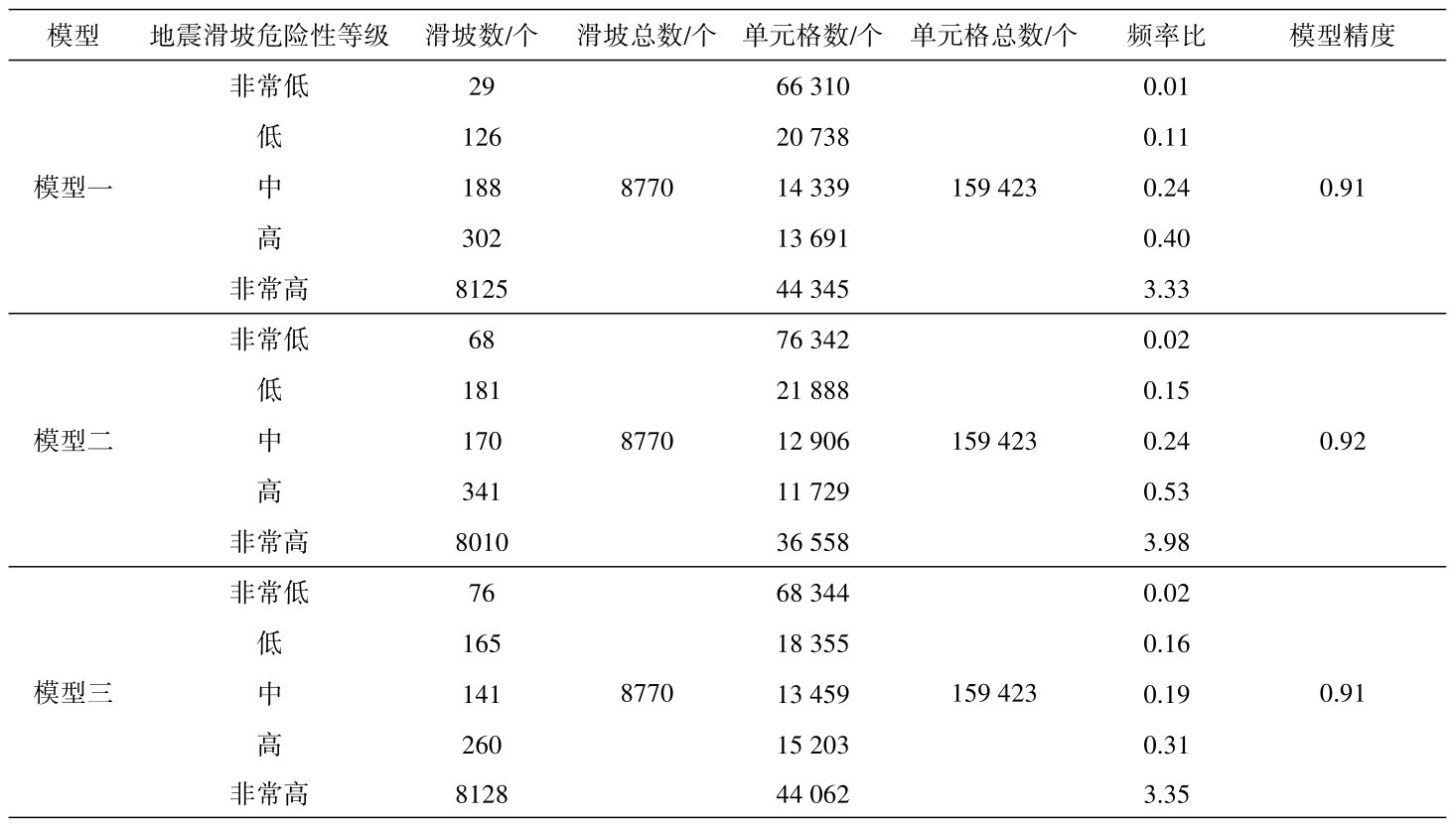
模型训练阶段的主要任务是通过误差反传算法来调节模型内部的权重值,直至神经网络的期望输出值和实际输出值之间的误差达到某个预先设置好的最小误差。以模型一为例,本阶段8770个地震滑坡点组成的正样本及随机选取等量的负样本所形成的数据集被分为两个子集:训练集和测试集。其中,训练集运用误差反传来调节模型内部权重,测试集则用于测试每次调节内部权重后的评估模型的具体精度。
在数据集的划分方面,主要有两种方法:一种是将数据集的80%作为训练集,剩余的20%作为测试集;也有一种是将数据集的70%作为训练集,剩余30%作为测试集。本次研究选取第一种划分方法对三个神经网络进行训练。
4.3 模型输出
神经网络训练完成后,将全部数据输入模型,模型通过前馈传播的方式输出结果。样本的模拟数值越接近0,说明此斜坡单元越稳定,发生地震滑坡的可能性越小;反之,样本的模拟数值越接近1,说明此斜坡单元越不稳定,发生地震滑坡的可能性越大。
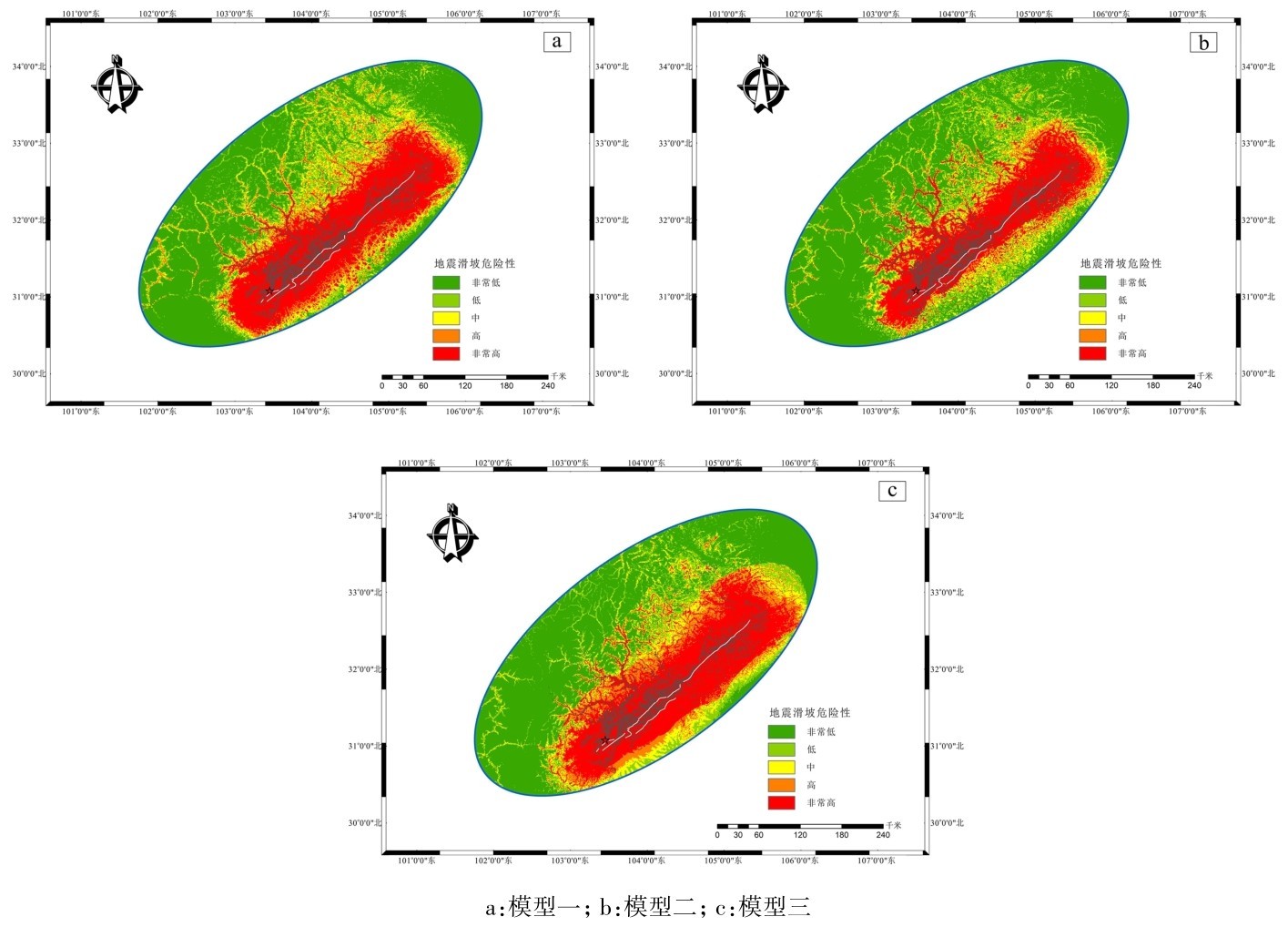
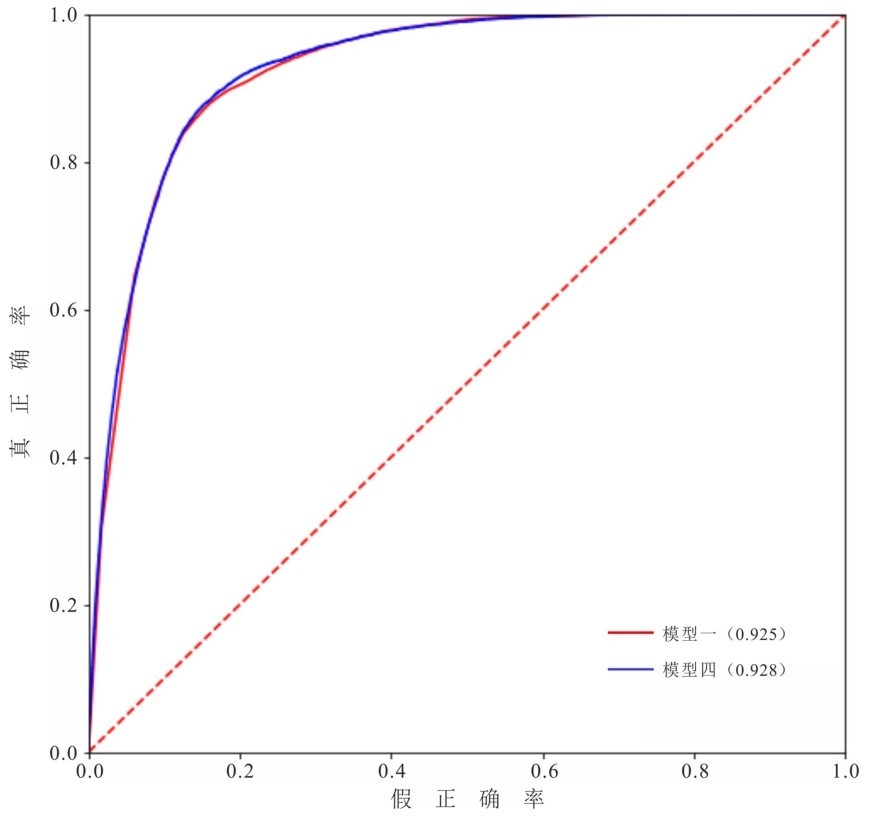
运用上述三个模型的评估结果,结合ArcGIS软件的空间分析功能,形成三组地震滑坡危险性分级。采用相等间隔分类方法将概率值划分为5个类别,分别对应非常低、低、中、高和非常高这5个地震滑坡危险性等级(图9)。图中可见,由三组模型所生成的图件都可以对研究区进行地震滑坡危险性等级的划分。但由模型一与模型三生成的区划图中,危险性等级为非常高的区域过大,宏观上对于非常高危险性等级区域的划分精度要选低于模型二。
图9 汶川地震区地震滑坡危险性分级Fig.9 Risk classification of seismic landslides in Wenchuan earthquake area
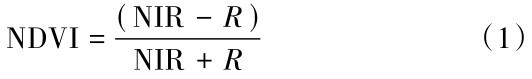
![图2 汶川地震滑坡影响因子平面图(据艾骁[35],2021,有修改) Fig.2 Plan figures of influencing factors of landslide in Wenchuan earthquake area(modified from Ai [35],2021)](2024年02期/2期0006_figure_006_004.jpg)