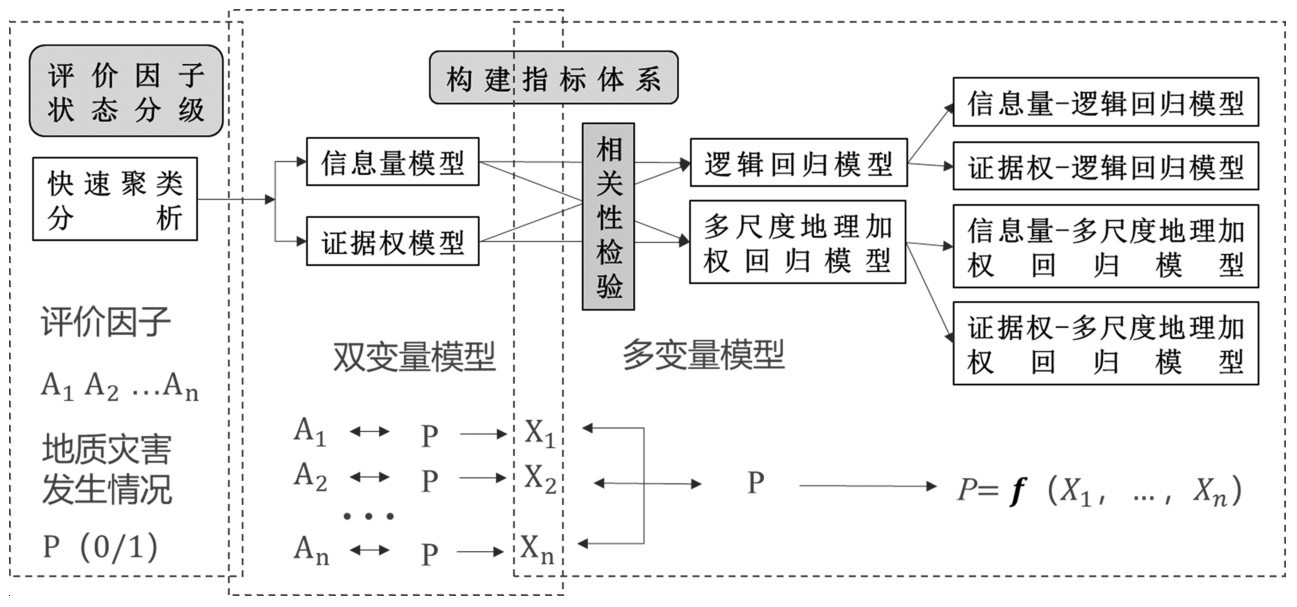
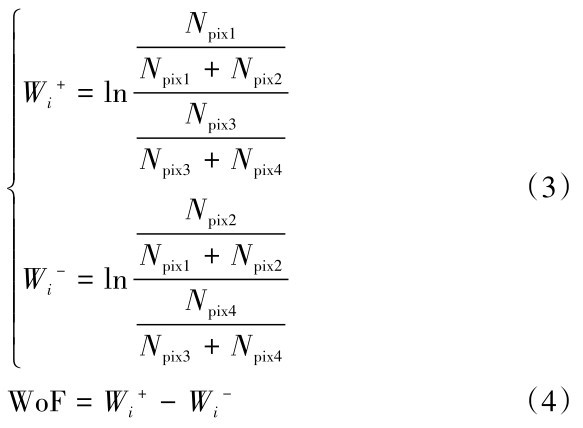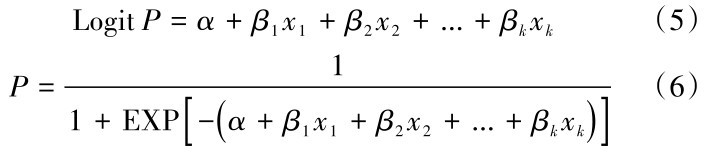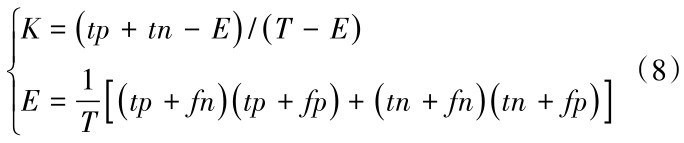指标体系的建立是危险性评价的基础,主要包括评价因子分级、量化、筛选及建立评价模型。本文基于快速聚类法对连续型评价因子数据进行分级,基于双变量模型的指标量化,基于相关性分析进行筛选,最后通过多变量模型构建关系式,以降低主观性对指标体系建立的影响,同时保证各评价因子之间的相互独立性和各因子与地质灾害的相关性,进而提高危险性评价的准确性。
3.1 评价因子选取及状态分级
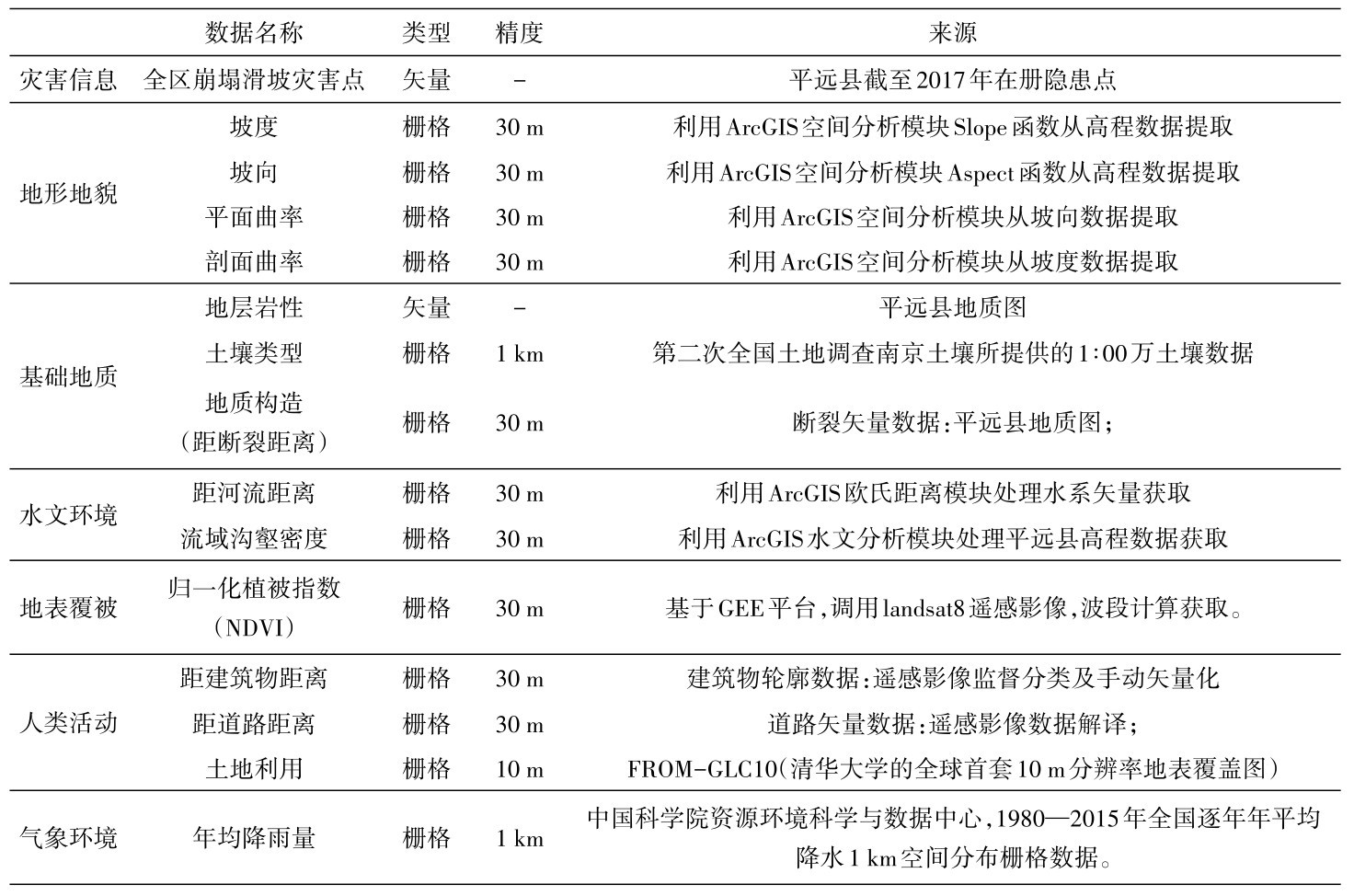
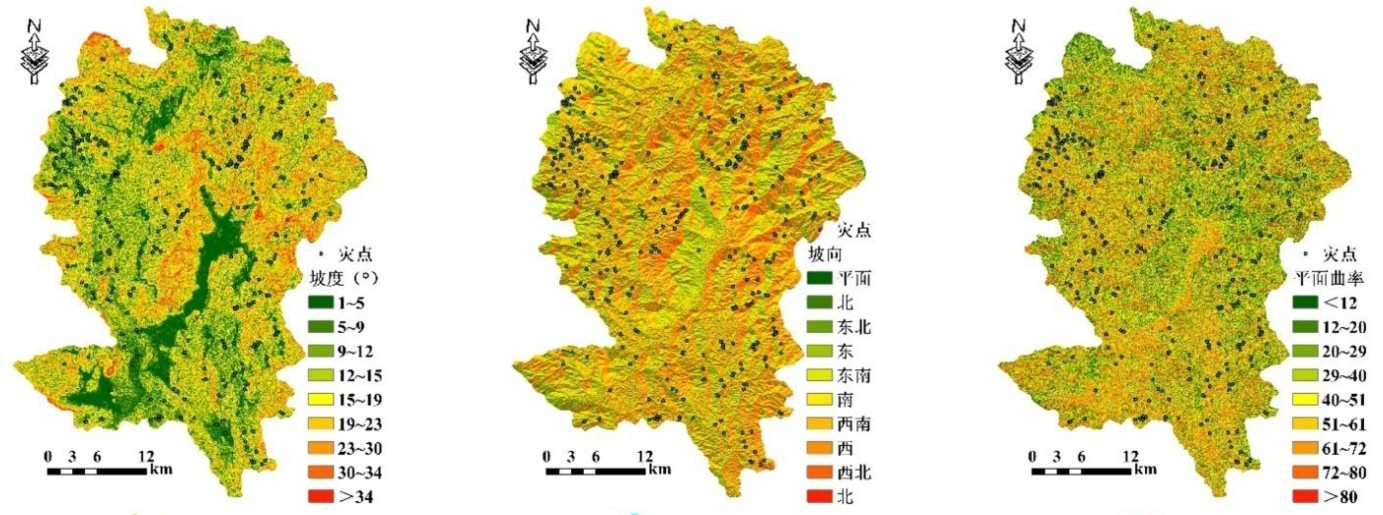
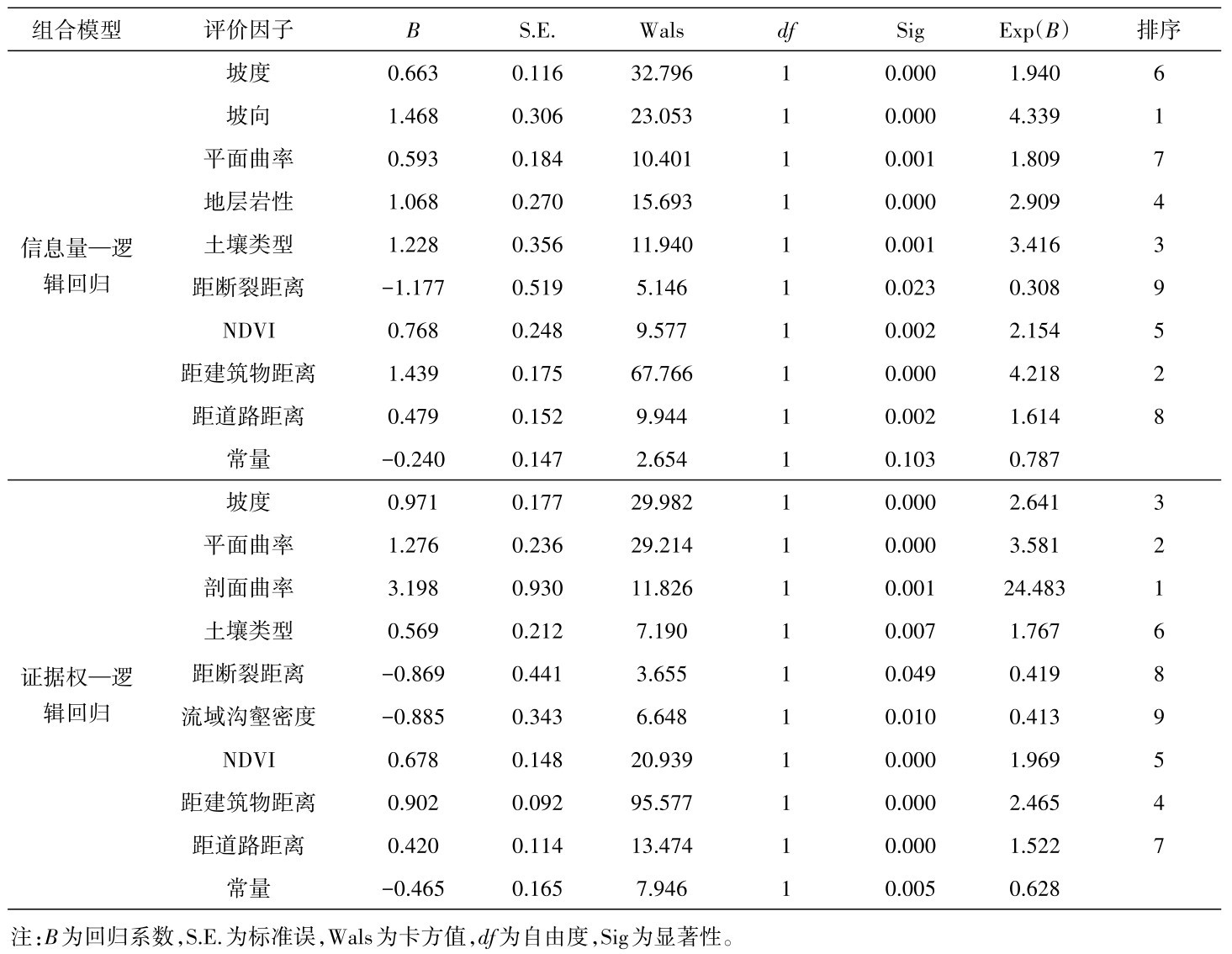
地质灾害是在多种条件和因素综合作用下发生的,因此在地质灾害危险性评价过程中,选取合适的评价因子是第一步也是最为基础的一步。主要包括孕灾环境和诱发因素两部分。本文结合滑坡、崩塌发生的内外因及研究区的地理地质特征,选取包括地形地貌、基础地质、水文环境、地表覆被的孕灾条件,以及包括气候环境、人类活动的诱发因素。得到最终的评价因子分级结果如图3。
3.1.1 地形地貌
地形地貌是崩塌、滑坡和泥石流等地质灾害产生的先决条件。斜坡的几何形态决定着斜坡体内应力的大小和分布,从而直接影响斜坡的稳定性与变形破坏模式。
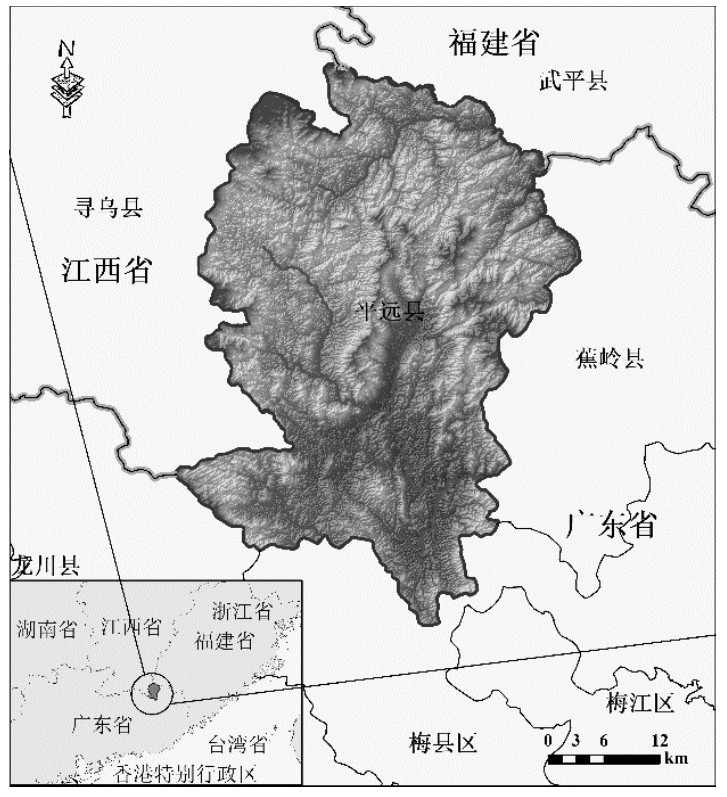
平远县属丘陵山区,山地、丘陵占总面积超过70%,其余为河谷盆地。整体西北部高于东南部,形成北高南低的地势,坡度北陡南缓,局部亦有东陡西缓,海拔高度大多在200~800 m之间。
本文选取坡度、坡向、平面曲率、剖面曲率4个相关因子。
3.1.2 基础地质
(1)地层岩性。地层岩性及岩性组合是直接指示斜坡岩土体“强度”的因素,基岩及堆积体的物理力学性质及其渗透性有所差异,直接影响坡体稳定性。它不仅影响区域滑坡、崩塌等的发育程度,同时可决定其类型及规模特征。
平远县地层复杂,少数乡镇有覆盖型可溶岩(岩溶发育),厚层易崩解的变质岩类、花岗岩类风化壳,第四系土层厚度大,不同区域不良地质体发育,境内出露的地层从老到新有震旦系(Z)、泥盆系(D)、石炭系(C)、二叠系(P)、侏罗系(J)、白垩系(K)、古近系(E)、第四系(Q)等,地层岩性包括白垩系下统优胜组(K2y)、侏罗纪晚侏罗世黑云母花岗岩(J 3 γ)、第四系全新统大湾镇组(Q h dw)等近30余类。
本文按照工程地质岩组分类进行后续统计分析。
(2)地质构造条件。地质构造条件对地质灾害发育的影响主要为:①通过影响地形地貌的形成进而影响地质灾害发育,在褶皱断裂附近的地形地势往往险峻,临空面发育,易发生崩塌等地质灾害;②通过改变岩土体的物理力学性质影响地质灾害的发育,一般在褶皱轴部和断裂带两侧,风化层厚,岩石破碎,裂隙发育,易发育灾害。与其他条件综合作用,使得地质灾害的分布在断裂构造附近越发密集。
平远县断裂构造纵横交错,在大断裂构造带的上下盘分布有大量的地质灾害点,在鹧鸪断裂、上举—猪麻坝断裂、长田圩断裂及中行—良畲断裂附近地质灾害点较多且展布方向与构造走向接近,一致呈长条形出现;在构造密集或交汇处,地质灾害点也密集且呈团块状分布。
本文选取距断层的欧氏距离来考虑地质构造活动对地质灾害的影响。
3.1.3 水文环境
水对边坡稳定性的影响形式主要包括流水冲刷、软化作用、浮力减重和动水压力。一方面,河流水系对坡岸的侵蚀切割,易导致该部分岩土体各项性能降低,易失去平衡。另一方面,长期的流水作用影响周围边坡地下水情况,从而直接影响土体受力。故本文选取距河流的欧氏距离和流域沟壑密度两个相关因子。
沟壑密度表示单位面积内侵蚀沟(或水文网)的长度,它代表了一个地区河流密集程度,是表征内外营力对地表侵蚀影响的重要指标。本文利用ArcGIS水文分析模块基于平远县30 m分辨率DEM数据,按照小流域单元分析计算流域沟壑密度。
3.1.4 地表覆被
植被覆盖度主要影响地表水对岩土体的入渗侵蚀程度,长期或严重的水力侵蚀下,岩土体各方面性质受到影响,强度降低,进而导致边坡变形失稳概率增加。因此本文采用归一化植被指数(NDVI)来表征其特征。
3.1.5 人类活动
自然因素是潜在内部因素,而不合理的人类工程活动则从外部加剧了地质灾害的发生和危害程度。近年来,随着社会经济的迅速发展和生活水平逐渐提高,削坡建房、修改扩建道路交通、兴建水利工程等人类工程活动难以避免地增多。据统计,截至2016年平远县由人类工程活动所造成的地质灾害点400处,占总数的78.7%。
本文选取距道路距离、距建筑物距离、土地利用3个因子来表征人类活动的影响。
3.1.6 气候环境
降雨是地质灾害发生的主要诱因之一,主要通过软化、泥化、冲刷和增加静水压力、动水压力等形式直接破坏岩土体物理力学性质。高强度降雨和长时间降雨情况下,降雨迅速入渗导致渗流力增加和岩土体强度折减,从而导致坡体极易失稳。平远县处亚热带季风气候区,西北部山岭陡峻,河流落差大,流量受降雨影响,夏秋季雨多,流量充沛,遇长时间大暴雨,地质灾害频发。
本文采用2010—2015年间平均降雨量作为评价因子数据。
3.2 双变量模型值计算
利用ArcGIS分析全部378处灾点样本在各评价因子分级状态中的空间分布情况,分别代入公式(2)~(4)。计算得出各分级状态的信息量I、证据权WoF值,结果见表2。
图3 各评价因子状态分级图Fig.3 The state classification diagram of each evaluation factor
表2 各评价因子状态分级及信息量(I)、证据权(WoF)值Table 2 The state classification of each evaluation factor,the information quantity(I)and weight of evidence(WoF)
3.3.2 回归系数计算
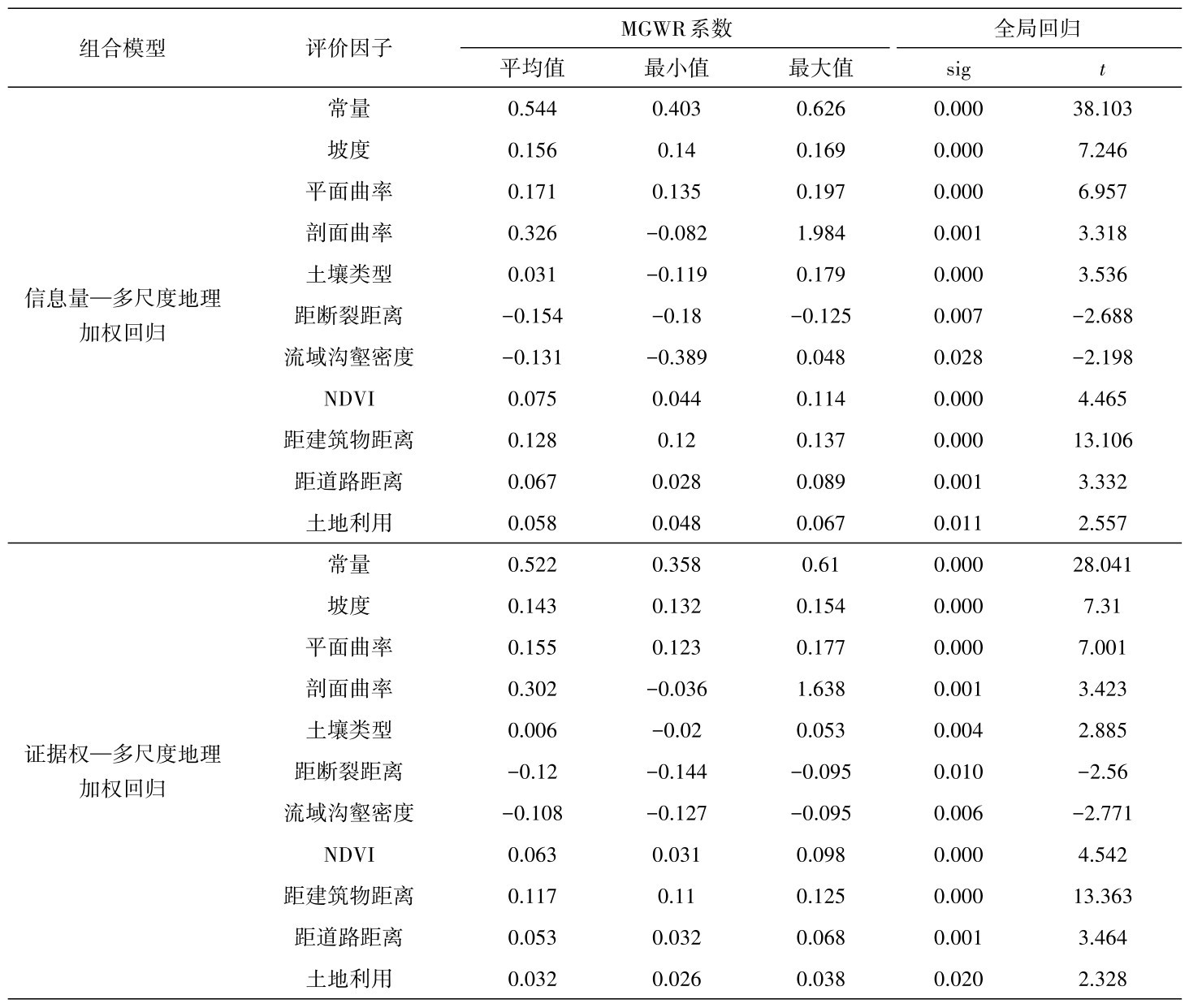
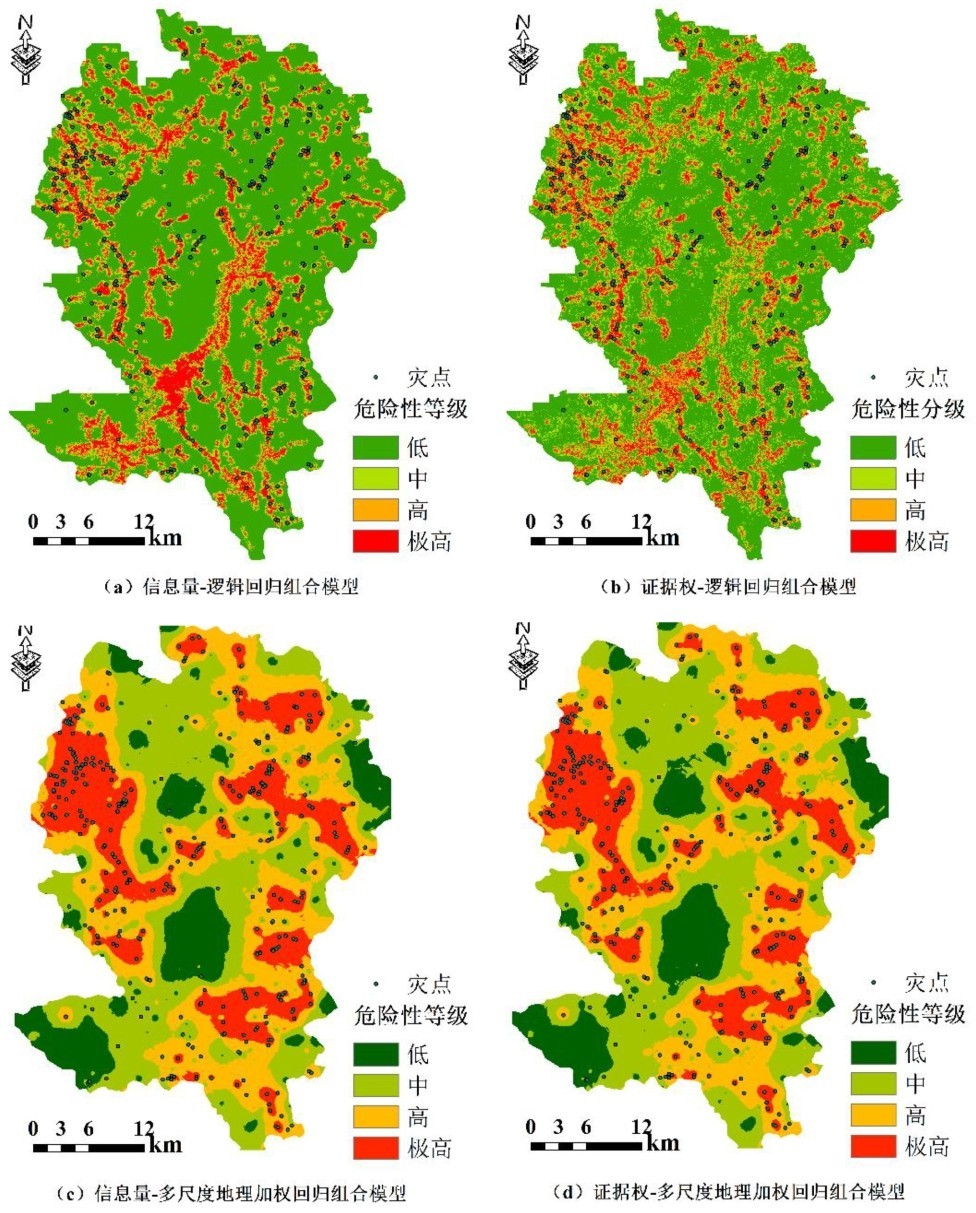
对通过筛选后的因子,采用SPSS进行二元逻辑回归,最终得到的结果如表4,显著性sig值均<0.05,说明组合模型通过检验。把结果中各评价因子的回归系数B作为该因子的权重β,常量为截距α,代入公式(6),利用ArcGIS进行栅格计算,即可得到每个栅格单元的危险性值。
从结果可以看出,三种组合模型最终的评价因子组成并不相同,且同一因子在2种组合模型中的权重也有区别。但权重大小排序变化不大。其中,距断裂距离、距道路距离几个因子在2种模型中权重都较小,排序靠后。
3.4 双变量+多尺度地理加权回归组合模型
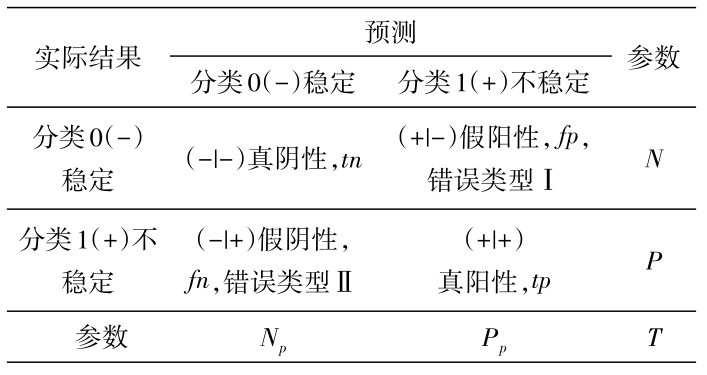
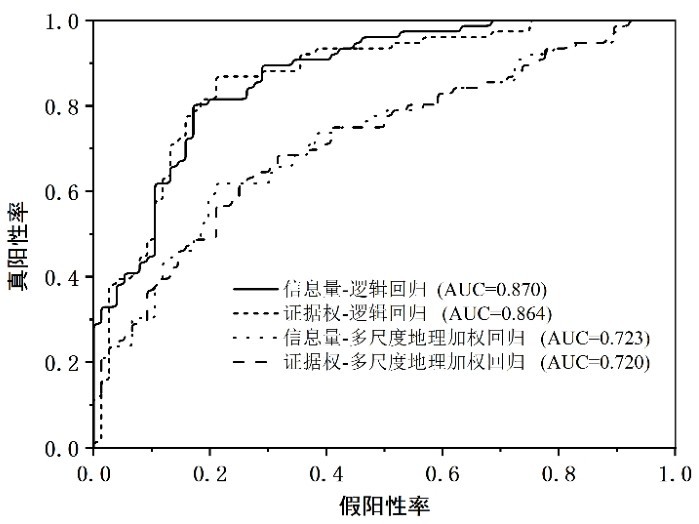
分别提取664个训练样本点的信息量I、证据权WoF模型值及经纬度坐标,并将是否发生地质灾害作为因变量(302个灾点样本赋值为1代表发生,302个非灾点样本赋值为0代表未发生),通过MGWR进行多尺度地理加权回归,并根据全局回归结果逐次剔除不满足显著性的因子,最终得到结果如表5,由于多尺度地理加权回归模型通常使用局部加权最小二乘方法进行逐点参数估计[11],得到的回归系数往往不是常量,而是随空间位置变化的变量,通过它的空间变化可以反映空间关系的非平稳性。故表5仅显示各评价因子回归系数的上下四分位数及平均值,可以看出各因子显著性值sig均<0.05,组合模型符合显著性检验。
表4 各评价因子逻辑回归系数Table 4 Logistic regression coefficients of each evaluation factor